Building a Compiler in Rust – Part 1
Translating 70s-style code into bytes with Rust. This guide walks through constructing a compiler for PL/0.
Building a lexer & choosing a language.
Not too complicated, right?
At the end of the day, our computers really only understand ones and zeros, the state of logical gates in a piece of finely-engraved silicon, and the layout of charges in chips of memory. Programs, data, noise – they all look the same. Yet, we're able to write instructions in a text-based programming language, that are somehow turned into the bits the computer speaks natively. How does that happen? With a compiled language, like Pascal, C, or Rust, the compiler does the job of turning the language into processor instructions, which are then assembled into bits and stored in special executable formats. Today, I want to explore the deep and beautiful ways in which a programming language can be translated into machine instructions by building a compiler.
What are we compiling?
This is a good question to start with. There are many languages out there – the major, general-purpose programming languages everyone thinks of, and then less common ones, like gnuplot instructions, or sudo configuration, or other Domain-Specific Languages (DSLs). We could write a program to interpret or compile any Turing-complete language ever invented, but most of them are complicated. Instead, we'll choose a simple, classic language that was invented specifically for learning compiler techniques with, PL/0.
PL/0 is an instructional language created by Niklaus Wirth, the same guy who invented Pascal, and contributed so much in the earlier days of computer science. He provided a basic compiler for it in his book Algorithms + Data Structures = Programs, which is a great read if you can find it. He wrote his in Pascal, which is difficult to understand if (like me) you aren't used to Pascal and its lack of abstractions around string processing. I like Dr. Brian Callahan's guide much better – it's written in C, and makes much more sense. I'll be following his guide for most of this series, and I highly recommend checking it out as well, especially when I glaze over details.
PL/0 is a simple language. Unless we extend it, it has one data type, VAR, which is an integer. Here is a simple program, stolen from Wikipedia.
VAR x, squ;
{Square x and load to squ}
PROCEDURE square;
BEGIN
squ := x * x
END;
BEGIN
x := 1;
{Square numbers from 1 to 10}
WHILE x < 11 DO
BEGIN
CALL square;
x := x + 1
END
END.There are not very many nice features here. I haven't even included I/O operations, but we'll deal with that later.
Our first job is to get this string of text into a string of important tokens. We can leave out whitespace and comments (the bits inside the {}). Now, how do we go about turning a string of text from a file into a string of tokens? We need a lexing program.
Building a Lexer
The main.rs file:
The first subtask is to make a program that can read a file. Since I want to make a nice, professional-looking program, I'll use the Clap CLI builder. This will let me run my program like so:
pl0rs -f path/to/source_code.pl0 -o path/to/targetRight now, we only need the -f part, for the file we're reading.
use std::path::PathBuf;
use std::process::exit;
use clap::{Parser, Subcommand};
use pl0rs::{self, lexer::lex, read_file, COMPILER_VERSION};
// Borrowed from Clap's boilerplate tutorial...
#[derive(Parser)]
#[command(version, about, long_about = None)]
struct Cli {
/// Path to the input file
#[arg(short, long, value_name = "FILE")]
file: Option<PathBuf>,
/// Turn debugging information on
#[arg(short, long, action = clap::ArgAction::Count)]
debug: u8,
}
fn main() {
let cli = Cli::parse();
let mut file = String::new();
let mut state = pl0rs::State::default();
// Print compiler version, &c.
println!("pl0rs -- PL/0 Compiler version {}", COMPILER_VERSION);
println!("(c) Ethan Barry, 2024. GPLv3 licensed.");
// Open the file and pass it into the file string.
// Program can terminate here with an error code.
if let Some(file_path) = &cli.file {
if let Ok(file_string) = read_file(file_path) {
file = file_string;
} else {
eprintln!("Error: No such file found.");
exit(1);
}
}
match cli.debug {
0 => {
println!("Debug mode is off.");
}
1 => {
println!("Debug mode is on.");
state.debug = true;
}
_ => {
println!("Don't be crazy. Defaulting to debug mode on.");
state.debug = true;
}
}
// Call the other modules.
match lex(&mut state, &file) {
Ok(res) => {
println!("Lexer succeeded.");
}
Err(e) => {
{
eprintln!("{e}");
exit(1);
} // A returned lexer error.
}
}
}That's a minimum working example. I also want to talk about project organization for a second. We know that this will be a complex program. It will need to be tested. Unit tests, declared in mod test and annotated with #[test] are not enough to validate an entire compiler. We also need integration tests. An integration test acts like an external application calling your program. It should be able to test all the functionality, by essentially acting as another fn main() in the codebase.
That's why you should organize the project like this:
┌ src
├─ main.rs
├─ lib.rs
├─ lexer.rs
╰ tests
Cargo.toml
...Your main.rs contains the glue logic that calls the real code in lib.rs. This way, your integration tests, in tests, can also call your library and test it against whatever test battery you create. It's a more advanced way of organizing the project.
The lib.rs file:
Now for the library where our compiler's functionality will live. We need to handle some housekeeping first. Let's declare a const VERSION so we can print it out when we want. All the real compilers display version numbers! Let's also declare our first module, the lexer.
//! File lib.rs
use std::{fs::File, io::Read, path::Path, process::exit};
pub mod lexer;
pub const COMPILER_VERSION: &str = "0.1.0";
pub struct State {
pub debug: bool,
pub line: u32,
}
impl Default for State {
fn default() -> Self {
Self {
debug: false,
line: 1,
}
}
}I also created a struct called State. It will store whether we're in debug mode, and what line we're on. It's a good idea to impl Default whenever we create a struct we want to use. I think this trait can also be derived, but this way was more fun.
Next, here's a function to read in a file and return it as a string.
//! File lib.rs
/// Can cause program termination with an error code.
pub fn read_file(filename: &Path) -> Result<String, String> {
let path = Path::new(filename);
// TODO: Eliminate unwrap.
if !path.extension().unwrap_or_default().eq("pl0") {
eprintln!("Error: File must have a .pl0 extension.");
exit(1);
}
let mut file = match File::open(path) {
Ok(file) => file,
Err(e) => return Err(format!("Couldn't open file: {e}")),
};
let mut contents = String::new();
match file.read_to_string(&mut contents) {
Ok(_) => Ok(contents),
Err(e) => Err(format!("Couldn't read file: {e}")),
}
}I'm enforcing that the file has a .pl0 extension, but that isn't really necessary, just fun. Once we've read in the file, we need to represent different tokens somehow. Dr. Callahan used #defines in his C program, but I think an enum will work nicely for Rust. The different types of tokens are these:
//! File lib.rs
#[derive(Debug, Clone)]
pub enum Token {
Ident(String),
Number(i64),
Const,
Var,
Procedure,
Call,
Begin,
End,
If,
Then,
While,
Do,
Odd,
Dot,
Equal,
Comma,
Semicolon,
Assign,
Hash,
LessThan,
GreaterThan,
Plus,
Minus,
Multiply,
Divide,
LParen,
RParen,
}
impl PartialEq for Token {
fn eq(&self, other: &Self) -> bool {
std::mem::discriminant(self) == std::mem::discriminant(other)
}
}
impl std::fmt::Display for Token {
// Needs a better format method.
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
write!(f, "{:?}", self)
}
}Each keyword, operator, and symbol has its own unique enum variant. Identifiers and numbers also get one. Here's where you choose your integer size; I chose i64, which means that I'll always try to parse a number in PL/0 source code into a 64-bit signed integer.
Brief funny story: I've done impl Display here by using a debug formatter. This is so I don't have to type {:?} every time I want to print a Token. Originally, I had used {}, which I assumed would just work. However, I kept getting stack overflow errors. I didn't realize it right away, but by calling write!(f, "{}", self) I was recursively calling fmt() and overflowing the stack. Just thought that was entertaining...
The lexer.rs file:
We have all the boilerplate. Now, we need to lex everything into the right sort of token. This will mean going through the file, character by character, and deciding what to do on the fly. An iterator would be nice!
Our lexer's primary function will take a string containing our PL/0 code, and a State that we can modify. It should return a Vec<Token>, but that might fail, so we'll return a Result<Vec<Token>, String> instead.
//! File lexer.rs
pub fn lex(state: &mut State, file: &str) -> Result<Vec<Token>, String> {
let mut chars = file.chars().peekable();
let mut comment = String::new();
let mut tokens: Vec<Token> = vec![];
// TODO!
Ok(tokens)
}First, let's process comments. In PL/0, comments are closed with braces, like this:
{this is a comment}When we see an opening brace, we'll skip through all the characters until we find the closing brace that matches it. If there is none, it's an error. We'll add this after the TODO! comment.
'lexer: loop {
if let Some(c) = chars.peek() {
if (*c).eq(&'{') {
chars.next(); // Consume the opening brace
'comment: for c in chars.by_ref() {
if c == '}' {
break 'comment;
}
if c.eq(&'\n') {
state.line += 1;
}
comment.push(c);
}
}
} else {
break 'lexer; // No more characters.
}
}There! We simply push all the characters in a comment to the comment string, in case we need them. Also be sure to increment the line count; we'll need that later.
The next trick is to discard whitespace between tokens. We can add some code to handle that in the same way we handle comments. After we've handled whitespace and comments, everything remaining is syntactically significant. A nested set of if-else statements will handle that. The entire lex() function is below.
//! File lexer.rs
pub fn lex(state: &mut State, file: &str) -> Result<Vec<Token>, String> {
let mut chars = file.chars().peekable();
let mut comment = String::new();
let mut tokens: Vec<Token> = vec![];
'lexer: loop {
if let Some(c) = chars.peek() {
if (*c).eq(&'{') {
chars.next(); // Consume the opening brace
'comment: for c in chars.by_ref() {
if c == '}' {
break 'comment;
}
comment.push(c);
}
} else if (*c).is_whitespace() {
if c.eq(&'\n') {
state.line += 1;
}
chars.next(); // Consume the whitespace.
} else if (*c).is_alphabetic() || (*c).eq(&'_') {
let token = identifier(&mut chars, state)?;
tokens.push(token);
} else if (*c).is_numeric() {
let token = number(&mut chars, state)?;
tokens.push(token);
} else if (*c).eq(&':') {
let token = assignment(&mut chars, state)?;
tokens.push(token);
} else {
let token = match *c {
'.' => Token::Dot,
'=' => Token::Equal,
',' => Token::Comma,
';' => Token::Semicolon,
'#' => Token::Hash,
'<' => Token::LessThan,
'>' => Token::GreaterThan,
'+' => Token::Plus,
'-' => Token::Minus,
'*' => Token::Multiply,
'/' => Token::Divide,
'(' => Token::LParen,
')' => Token::RParen,
_ => {
return Err(format!("Unknown token on line {}", state.line));
}
};
tokens.push(token);
chars.next();
}
} else {
break 'lexer; // No more characters
}
}
Ok(tokens)
}A diagram might make the code easier to understand. I'll draw it as a state machine!
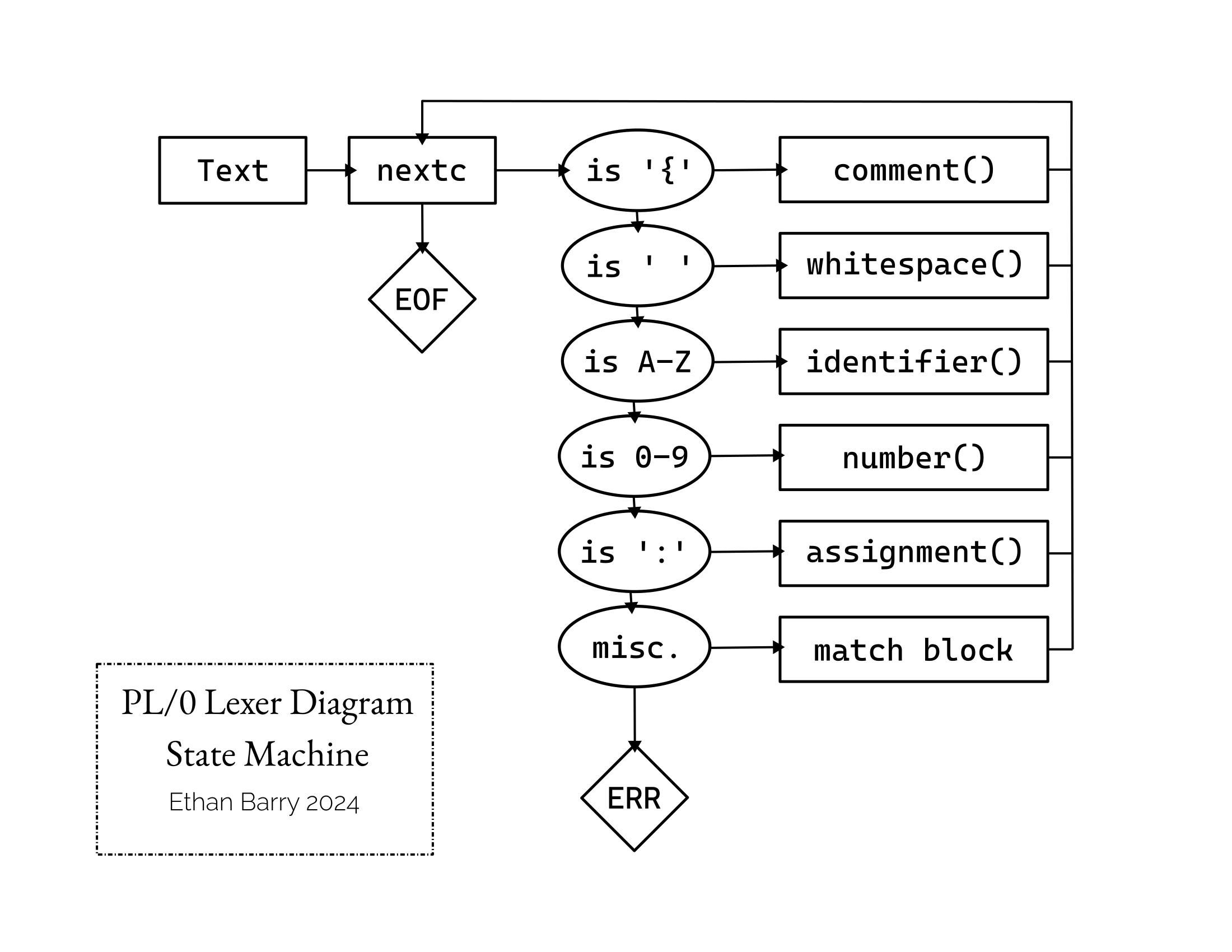
Any of the last four boxes on the right add a token to the Vec<Tokens> that we're storing the tokenized code in. Also note the assignment() block. It is called when the lexer finds a colon. In the PL/0 grammar, the assignment operator is :=, and the only place a colon can occur is in the assignment operator. So, if we find a colon without an equals sign, it's an error. Let's write that method now.
//! File lexer.rs
pub fn assignment(chars: &mut Peekable<Chars<'_>>, state: &mut State) -> Result<Token, String> {
chars.next(); // Consume the ':' character.
if let Some(c) = chars.peek() {
if (*c).eq(&'=') {
chars.next();
Ok(Token::Assign)
} else {
Err(format!("Unknown token ':' on line {}", state.line))
}
} else {
Err(format!("Unterminated assignment on line {}", state.line))
}
}This function is pretty straightforward. The if let syntax is a clean way to deal with the iterator. This method advances the iterator right away, because it is only ever called on a ':'. (If it were called somewhere besides a colon, this would be a logic error. You can make a note of that and move on.)
Words and Numbers
Now there are just two functions left to implement, number() and identifier(). These both need to take one character at a time, until they encounter whitespace, or something that isn't legally a number or identifier. Dr. Callahan suggested extending PL/0 to allow breaking up large integers with underscores, like we can do in modern languages. We'll add that as well.
Also notice that the function lex() calls identifier() whenever it sees an alphabetic character or underscore. This includes keywords and variable names. It will have to distinguish them, and return the correct Token enum variant.
//! File lexer.rs
pub fn identifier(chars: &mut Peekable<Chars<'_>>, state: &mut State) -> Result<Token, String> {
let mut idt = String::new();
loop {
// Push characters onto idt one by one.
if let Some(c) = chars.peek() {
if (*c).is_alphanumeric() || (*c).eq(&'_') {
idt.push(*c);
chars.next();
} else {
break;
}
} else {
// Was a None.
return Err(format!("Unterminated identifier on line {}", state.line));
}
}
let token = match idt.to_lowercase().as_str() {
"const" => Token::Const,
"var" => Token::Var,
"procedure" => Token::Procedure,
"call" => Token::Call,
"begin" => Token::Begin,
"end" => Token::End,
"if" => Token::If,
"then" => Token::Then,
"while" => Token::While,
"do" => Token::Do,
"odd" => Token::Odd,
_ => Token::Ident(idt),
};
Ok(token)
}
pub fn number(chars: &mut Peekable<Chars<'_>>, state: &mut State) -> Result<Token, String> {
let mut num = String::new();
loop {
if let Some(c) = chars.peek() {
if (*c).is_numeric() || (*c).eq(&'_') {
num.push(*c);
chars.next();
} else {
break;
}
} else {
// Was a None.
return Err(format!("Unterminated number on line {}", state.line));
}
}
if let Ok(res) = num.parse::<i64>() {
Ok(Token::Number(res))
} else {
Err(format!("Invalid number at line {}", state.line))
}
}Notice that identifier() allows variables with underscores or numbers after an initial letter or underscore, so x_0 and _1000 are legal variable names. number() parses the complete number string into an i64, as we decided earlier.
At the risk of making the article too long for anyone to read, I put the complete lexer.rs file below, as written up to this point.
//! File lexer.rs (complete)
use std::{iter::Peekable, str::Chars};
use crate::{State, Token};
/// ## Preconditions
///
/// - Must only be called for characters which can begin an identifier.
pub fn identifier(chars: &mut Peekable<Chars<'_>>, state: &mut State) -> Result<Token, String> {
let mut idt = String::new();
loop {
// Push characters onto idt one by one.
if let Some(c) = chars.peek() {
if (*c).is_alphanumeric() || (*c).eq(&'_') {
idt.push(*c);
chars.next();
} else {
break;
}
} else {
// Was a None.
return Err(format!("Unterminated identifier on line {}", state.line));
}
}
let token = match idt.to_lowercase().as_str() {
"const" => Token::Const,
"var" => Token::Var,
"procedure" => Token::Procedure,
"call" => Token::Call,
"begin" => Token::Begin,
"end" => Token::End,
"if" => Token::If,
"then" => Token::Then,
"while" => Token::While,
"do" => Token::Do,
"odd" => Token::Odd,
_ => Token::Ident(idt),
};
Ok(token)
}
pub fn number(chars: &mut Peekable<Chars<'_>>, state: &mut State) -> Result<Token, String> {
let mut num = String::new();
loop {
if let Some(c) = chars.peek() {
if (*c).is_numeric() || (*c).eq(&'_') {
num.push(*c);
chars.next();
} else {
break;
}
} else {
// Was a None.
return Err(format!("Unterminated number on line {}", state.line));
}
}
if let Ok(res) = num.parse::<i64>() {
Ok(Token::Number(res))
} else {
Err(format!("Invalid number at line {}", state.line))
}
}
pub fn assignment(chars: &mut Peekable<Chars<'_>>, state: &mut State) -> Result<Token, String> {
chars.next(); // Consume the ':' character.
if let Some(c) = chars.peek() {
if (*c).eq(&'=') {
chars.next();
Ok(Token::Assign)
} else {
Err(format!("Unknown token ':' on line {}", state.line))
}
} else {
Err(format!("Unterminated assignment on line {}", state.line))
}
}
pub fn lex(state: &mut State, file: &str) -> Result<Vec<Token>, String> {
let mut chars = file.chars().peekable();
let mut comment = String::new();
let mut tokens: Vec<Token> = vec![];
'lexer: loop {
if let Some(c) = chars.peek() {
if (*c).eq(&'{') {
chars.next(); // Consume the opening brace
'comment: for c in chars.by_ref() {
if c == '}' {
break 'comment;
}
if c.eq(&'\n') {
state.line += 1;
}
comment.push(c);
}
} else if (*c).is_whitespace() {
if c.eq(&'\n') {
state.line += 1;
}
chars.next(); // Consume the whitespace.
} else if (*c).is_alphabetic() || (*c).eq(&'_') {
let token = identifier(&mut chars, state)?;
tokens.push(token);
} else if (*c).is_numeric() {
let token = number(&mut chars, state)?;
tokens.push(token);
} else if (*c).eq(&':') {
let token = assignment(&mut chars, state)?;
tokens.push(token);
} else {
let token = match *c {
'.' => Token::Dot,
'=' => Token::Equal,
',' => Token::Comma,
';' => Token::Semicolon,
'#' => Token::Hash,
'<' => Token::LessThan,
'>' => Token::GreaterThan,
'+' => Token::Plus,
'-' => Token::Minus,
'*' => Token::Multiply,
'/' => Token::Divide,
'(' => Token::LParen,
')' => Token::RParen,
_ => {
return Err(format!("Unknown token on line {}", state.line));
}
};
tokens.push(token);
chars.next();
}
} else {
break 'lexer; // No more characters
}
}
Ok(tokens)
}We have a fully functional lexer for our compiler, that tokenizes and understands PL/0! Congratulations! Our next steps come in the next post in this series, where we'll parse the Vec<Token> that our lexer spits out.
As always, thank you for reading! If you have suggestions or comments, please write me at ethan.barry@howdytx.technology. Have a great day!